Table of contents
简介
这是一个简单的项目,其目的是为了抓取网页中的图片,和相关的信息。例如如果想要抓取电影网站的图片和电影信息(title, director, cast, date, rate, category)。然后再把这些信息通过pymysql储存到MySQL中。 本文的大部分思路来源于Beautiful Soup: Build a Web Scraper With Python。
安装必要的包
- 安装pymsql :
pip3 install PyMySQL,可参考rurunoob. - 安装beautifulsoup :
pip install beautifulsoup4。 使用beautifulsoup 来提取页面中的内容。
查看页面内容
首先应该在想要抓取的网站中熟悉页面。例如想在Indeed网站找Machine Learning 的工作。我们在地址栏中可以找到一些信息,例如https://www.indeed.com/jobs?q=,这是搜索的前缀,如果想搜索工作Machine Learning可以这样修改https://www.indeed.com/jobs?q=Machine+Learning。如果想限定地方可以使用&来表示同时满足条件:https://www.indeed.com/jobs?q=Machine+Learning&l=New+York。
然后找到相关的HTML页面,通过浏览器的源代码查看网页的信息所在的位置。html 网页都是结构化组织的,可以一层层地查找,如果有标签有id则是可以直接搜寻到。在Mac中是使用fn+F12在 Chrome中查看源代码。然后通过在源代码界面在搜索框中查找具体的内容来快速锁定信息所在的位置。
以下使用豆瓣Top250 来进行解释说明。
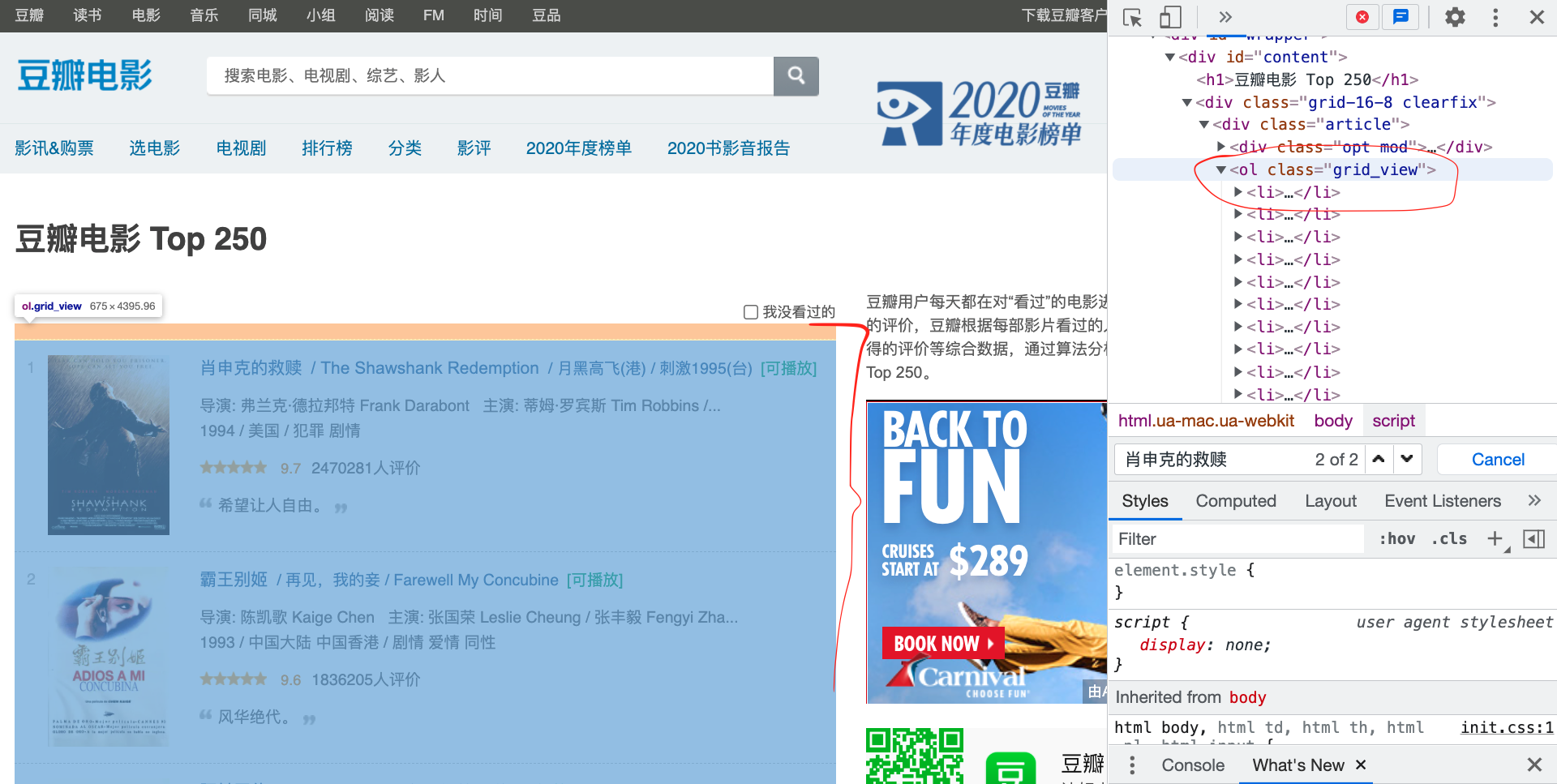
在上面的图片中我们通过在搜索框中输入 肖申克的救赎, 可以找到前25个电影的基本信息。后面可以进入其中一个再进行仔细查看。如下
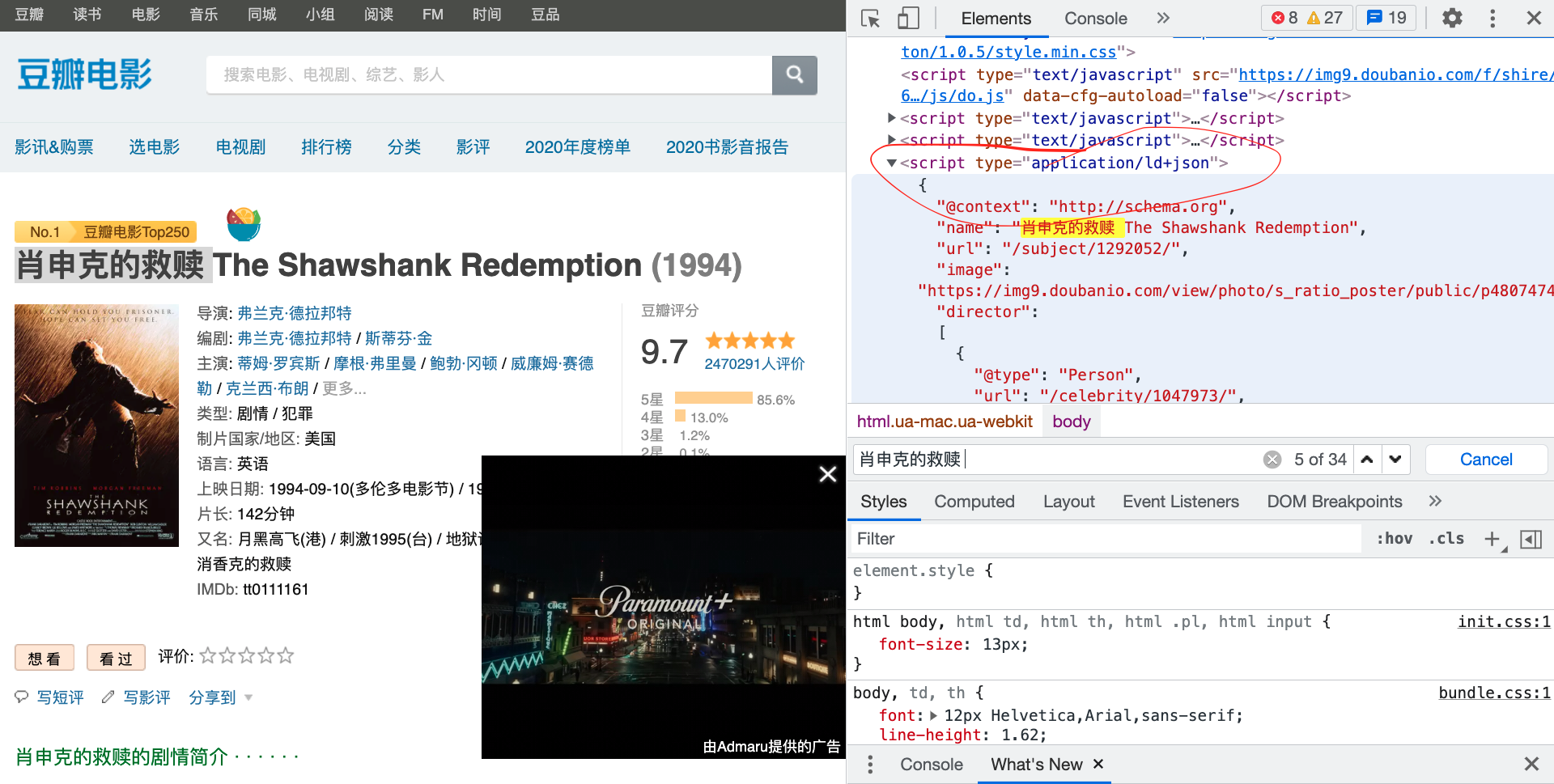
可以看到在页面中在scrip中有详细的信息,可以把其爬下来。
爬虫过程
使用requests获取网页内容
import requests
from bs4 import BeautifulSoup
URL = "https://realpython.github.io/fake-jobs/"
page = requests.get(URL)
print(page.text)
soup = BeautifulSoup(page.content, "html.parser")
Note:使用requests.get(URL)来获取网页内容。 然后再使用Beautifulsoup提取网页的内容。使用page.content 要比使用page.text要好,因为page.content保存的是raw bytes。使用page.text可能在parser时出现格式错误。
html.parser参数表示对html 进行分割。
提取soup中的内容
- 如果标签中有id,则可以直接提取其内容
results = soup.find(id='Container')
print(results.prettify())
使用
results.prettify()输出的格式是美观的。
- 标签中有class name
job_elements = results.find_all("div", class_="card-content")
注意
class_有一个下划线
- 通过标签中的内容来提取
首先知道标签是哪一个,和自己要找的内容。
python_jobs = results.find_all(
"h2", string=lambda text: "python" in text.lower()
)
提取h2标签中含有python的所有h2 标签。string 参数表示要寻找的内容。可以传递string, regular expression, function,参考bs4 string
提取内容
使用.text 来获取wraper 中的text
content = results.text
job = job_elements.text
有了text文本内容后, 后面就是通过python来组织提取信息了。