Table of contents
Association rule mining
Concept
关联规则(Association Rules)是反映一个事物与其他事物之间的相互依存性和关联性,是数据挖掘的一个重要技术,用于从大量数据中挖掘出有价值的数据项之间的相关关系。
常见的购物篮分析
该过程通过发现顾客放人其购物篮中的不同商品之间的联系,分析顾客的购买习惯。通过了解哪些商品频繁地被顾客同时购买,这种关联的发现可以帮助零售商制定营销策略。其他的应用还包括价目表设计、商品促销、商品的排放和基于购买模式的顾客划分。
详细的概念解释可参考CSDN
Methods
常用的算法有Aprior,FP-Tree,GSP, CBA。后面三种算法是旧雨Aprior算法发展而来。对其进行了一定程度的优化。
Aprior算法可参考刘建平Pinard的解释。
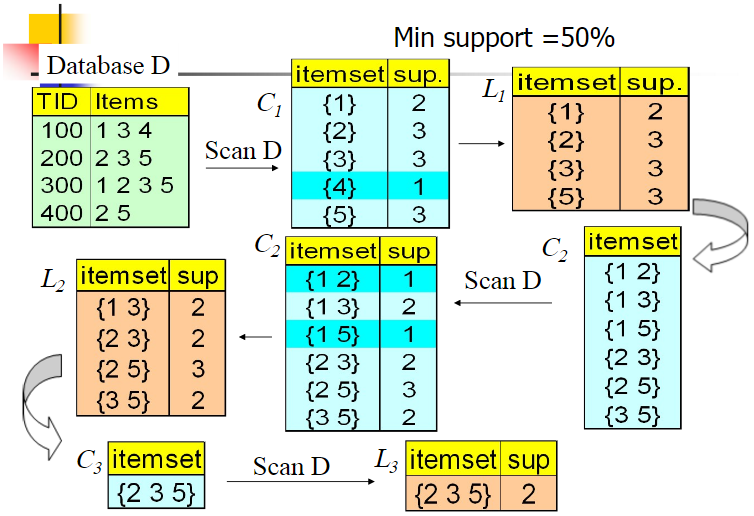
Aprior算法有以下缺点:
- The size of candidate itemsets could be extremely large
- High costs on counting support since we have to scan the itemset database over and over again
为了克服以上缺点,出现了FP-Tree. FP-Tree 只需要扫描两次数据。一次是家里项头表,第二次是删除掉出现频次低的项,并进行排序。
FP-Tree的核心思想是:More frequently occurring items will have better chances of sharing items
FP-Tree 算法可参考FP Tree算法原理总结,其解释的很清楚。
coreference resolution(CR)
Coreference resolution (CR) is the task of finding all linguistic expressions (called mentions) in a given text that refer to the same real-world entity. After finding and grouping these mentions we can resolve them by replacing, as stated above, pronouns with noun phrases.

Lemmatisation and Stemming
NLP Lemmatisation(词性还原) 和 Stemming(词干提取) NLTK pos_tag word_tokenize.
这属于text的前处理部分。目的是为了提取出来的词的一致性。例如dogs 和dog在意思上是一样的。通过Lemmatisation可以都转化为dog。
词干提取有时会破坏词的意思。使其看不出原来的词意。
详细内容可参考青盏的解释。
在我做的project中需要提取entities,因此我在pos_tag后只提取tag 开头为NN的名词。如下
from nltk import pos_tag
from nltk import word_tokenize
tags = pos_tag(word_tokenize(d)) # get pos tag of each word
ents = [w for w,t in tags if t.startswith('NN')] # get the entities
ents = [lemmatizer.lemmatize(w) for w in ents] # lemmatization
ents = [w for w in ents if w.lower() not in all_stop_words] # get rid of stop words