Titanic Disaster 二分类问题
3. Model Selection and Parameters Tuning
Table of contents
1. 可以使用 sklearn 中的metrics 中的function来对二分类的模型进行评估
from sklearn import metrics
def get_scores(y_preds,y):
return {
"Accuracy":metrics.accuracy_score(y_preds,y),
'Precision':metrics.precision_score(y_preds,y),
'Recall':metrics.recall_score(y_preds,y),
'F1':metrics.f1_score(y_preds,y),
'ROC_AUC':metrics.roc_auc_score(y_preds,y)
}
from sklearn import metrics
def get_scores(y_preds,y):
return {
"Accuracy":metrics.accuracy_score(y_preds,y),
'Precision':metrics.precision_score(y_preds,y),
'Recall':metrics.recall_score(y_preds,y),
'F1':metrics.f1_score(y_preds,y),
'ROC_AUC':metrics.roc_auc_score(y_preds,y)
}2. 使用sklearn.model_selection 中的 train_test_split 对数据进行分割,返回值是 train-test 对
Note: sklearn.model_selection.train_test_split(arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)[] Returns: spliting list, length = 2len(arrays) List containing train-test split of inputs. source
3. 模型的选择:用于二分类的模型有很多,最后可以将这些已经训练好的模型进行整合(ensemble),评估所有模型的结果后得出 最终 结果。
from sklearn.tree import DecisionTreeClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
from sklearn.linear_model import LogisticRegression
from sklearn import svm
from catboost import CatBoostClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForesClassifier,VotingClassifier
4. 使用function 一次性训练 多个模型。
def train_model(model):
model_ = model
model_.fit(X_train,y_train)
y_preds = model_.predict(X_val)
return get_scores(y_preds,y_val)
model_list = [
DecisionTreeClassifier(random_state=42),
RandomForestClassifier(random_state=42),
XGBClassifier(random_state=42),
LGBMClassifier(random_state=42, is_unbalanced=True),
svm.SVC(random_state=42,verbose=0),
AdaBoostClassifier(random_state=42)
]
model_names = [
'Decision Tree', 'Random Forest', 'XGBoost', 'Light GBM', 'Logistic Reg', 'SVM', 'CatBoost', 'AdaBoost'
]
scores = pd.DataFrame(columns=['Name', 'Accuracy', 'Precision', 'Recall', 'F1', 'ROC_AUC'])
for i in range(len(model_list)):
score = train_model(model_list[i]) # 训练第i个模型,并返回score
scores.loc[i] = [model_name[i]] + list(score.values()) # 把第i个模型的结果放到DataFrame中的第i行中
Note: train_model 函数中的fit 和 predict 可以换成自己写的函数,然后根据model_list中的model来进行训练模型和预测分数。并把分数储存到DataFrame中,方便后面生成图。
5.使用GridSearchCV 进行调参数
from sklearn.model_selection import GridSearchCV
tuned_models = []
def grid_search_util(i):
grid_search = GridSearchCV(estimator=model_list[i], param_grid=param_grids[i],
cv=3,n_jobs=-1,verbose=1)
grid_search.fit(X_train,y_train)
return grid_search.best_estimator_
Node: GridsearchCV 中的estimator 是要评估的模型, param_grid 是要尝试的参数,param_grid 是一个字典,dictionary。 cv 是交叉验证的次数。使用fit来训练模型,返回最好的model:
grid_search.best_estimator_,关于GridsearchCV 的详细解释可参考sklearn
例如使用的模型是DecisionTreeClassifier, param_grid 可如下
{
'max_depth':[5,7,10,50],
'min_sample_leaf':[1,2,4,6],
'min_sample_split':[2,4,8,10]
}
6.使用matplotlib.pyplot 展示模型效果。
figure, axis = plt.subplots(2,3,) # 2 行 3 列
figure.set_figheight(15)
figure.set_figwidth(20)
for i in range(2):
for j in range(3):
axis[i,j].set_xlim([0.5,0.9]) #设置x轴的范围
# y轴是name, x轴是width, width的高度是0.5
axis[0,0].barh(y=scores['Name'],width=scores['Accuracy'],height=0.5)
axis[0,0].set_title('accuracy Score') # 设置0行0列图的title
axis[0,1].barh(y=scores['Name'],width= scores['Precision'],height=0.5)
axis[0,1].set_title('Precision')
axis[1,0].barh(y=scores['Name'],width=scores['Recall'],height=.5)
axis[1,0].set_title('Recall')
axis[1,2].barh(scores['Name'],scores["F1"],height=0.5)
axis[1,2].set_title('F1')
axis[0,2].barh(y=scores['Name'],scores['ROC_AUC'],height=0.5)
axis[0,2].set_title('ROC_AUC')
axis[1,1].set_visible(False) # 使第1行1列的图不显示
plt.show()
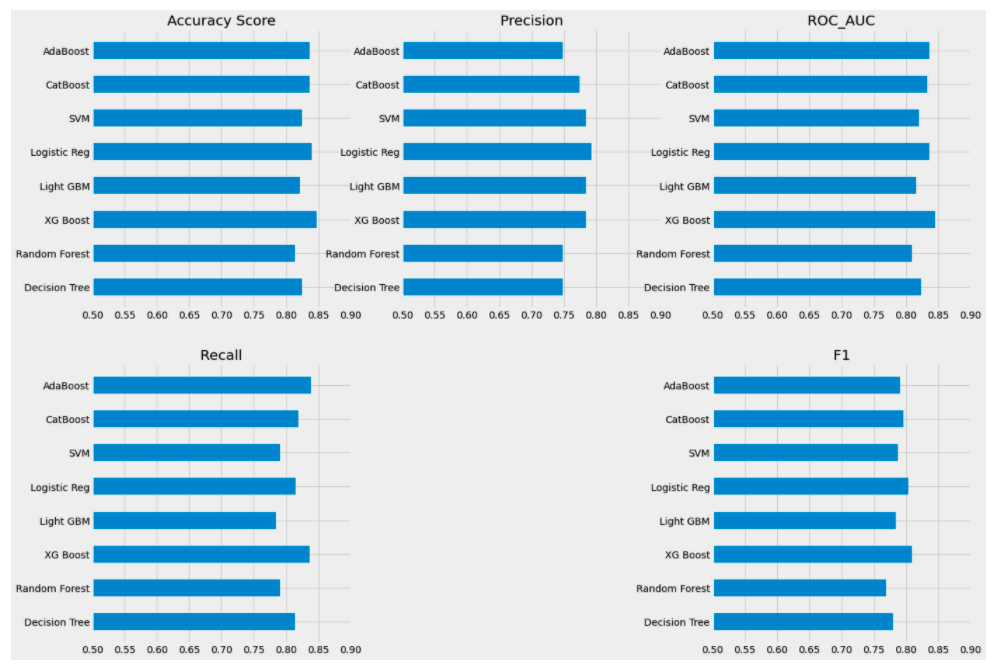
Note: 先使用plt.subplots(2,3) 生成2行3列的多个图。使用axis对具体的图进行操作,与操作数组的方式相同。 axis[0,0].barh() 生成横行bar图。 axis[1,1].set_visible(False) 可以指定某个图不显示