Table of contents
- Python log module
- pass sensitive variables to the python script
- Use try and except to catch error and still show the wrong file and line number
- Write document for python function and class
- decorator
- Create temparory file and folder
- Structure the project folder
- install packages
- Python
- 使用dateutil 对string转换成datetime
- 使用yml格式作为config 文件格式
- use shutil to copy files
- use
pipreqsto extract the packages used in the script - use glob to search specific files in specific depth
- use * to unpack the list
- format string
- print space
- set
- defaultdict
- bisect
- sort OR sorted
- range
- ord
- heapq
- deque
- one line equation
- re
- openpyxl
Python log module
The logging python module official document
Here’s some examples of logging
import logging
logger = logging.getLogger('my_logger')
# format to show the logging
format1 = '%(asctime)s - %(levelname)s - %(message)s'
format2 = '%(asctime)s:%(filename)s:%(funcName)s:%(lineno)d:%(levelname)s:%(message)s'
# in basicConfig function, you can specify the output file, the format, and the level of logging
logging.basicConfig(filename='example.log', format=format2, level=logging.DEBUG)
logger.debug('This message should go to the log file')
logger.info('So should this')
logger.warning('And this, too')
logger.error('And non-ASCII stuff, too, like Øresund and Malmö')
logger.warning('%s before you %s', 'Look', 'leap!')
name = 'Jone'
logger.warning(f'Looking {name}')
def getLog():
logger.warning('this is in function')
getLog()
Output of above logging code:
2025-10-10 09:53:51,578:testLogging.py:<module>:13:DEBUG:This message should go to the log file
2025-10-10 09:53:51,578:testLogging.py:<module>:14:INFO:So should this
2025-10-10 09:53:51,578:testLogging.py:<module>:15:WARNING:And this, too
2025-10-10 09:53:51,578:testLogging.py:<module>:16:ERROR:And non-ASCII stuff, too, like Øresund and Malmö
2025-10-10 09:53:51,578:testLogging.py:<module>:18:WARNING:Look before you leap!
2025-10-10 09:53:51,578:testLogging.py:<module>:21:WARNING:Looking Jone
2025-10-10 09:53:51,578:testLogging.py:getLog:24:WARNING:this is in function
Log Error exception
import logging
# Configure the logging settings
logging.basicConfig(filename='error.log', level=logging.ERROR, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
try:
# Code that may raise an exception
result = 10 / 0
except Exception as e:
# Log the exception details
logging.error("An exception occurred: %s", str(e), exc_info=True)
Output of above code
2025-10-10 09:41:32,089 - root - ERROR - An exception occurred: division by zero
Traceback (most recent call last):
File "loggerError.py", line 19, in <module>
result = 10 / 0
ZeroDivisionError: division by zero
pass sensitive variables to the python script
- create a
.envfile in the project folder.# .env file in the project folder key=your-secret - in the python script file, use
os,dotenvto use the variables as shwon below.import os from dotenv import load_dotenv load_dotenv() key = os.getenv(key)
Use try and except to catch error and still show the wrong file and line number
import traceback
try:
1 / 0
except Exception:
traceback.print_exc()
## output
Traceback (most recent call last):
File "/home/test.py", line 5, in <module>
x = 1 / 0
ZeroDivisionError: division by zero
import traceback
try:
# Code that might raise an exception
x = 1 / 0
except Exception as e:
tb = traceback.extract_tb(e.__traceback__)[-1]
print(f"Error in file: {tb.filename}, line: {tb.lineno}, function: {tb.name}")
## output
Error in file: /home/test.py, line: 5, function: <module>
Write document for python function and class
Here’s a exaple using Sphinx markup
def send_message(sender, recipient, message_body, priority=1) -> int:
"""
Send a message to a recipient.
:param str sender: The person sending the message
:param str recipient: The recipient of the message
:param str message_body: The body of the message
:param priority: The priority of the message, can be a number 1-5
:type priority: integer or None
:return: the message id
:rtype: int
:raises ValueError: if the message_body exceeds 160 characters
:raises TypeError: if the message_body is not a basestring
"""
return 1
decorator
Here’s is a good boilerplate template for building more complex decorators from RealPython
import functools
def decorator(func):
@functools.wraps(func)
def wrapper_decorator(*args, **kwargs):
# Do something before
value = func(*args, **kwargs)
# Do something after
return value
return wrapper_decorator
Here’s a real example ellustrated in realPython
import functools
import time
# ...
def timer(func):
"""Print the runtime of the decorated function"""
@functools.wraps(func)
def wrapper_timer(*args, **kwargs):
start_time = time.perf_counter()
value = func(*args, **kwargs)
end_time = time.perf_counter()
run_time = end_time - start_time
print(f"Finished {func.__name__}() in {run_time:.4f} secs")
return value
return wrapper_timer
Create temparory file and folder
When you upload file to Flask server, you’d like to save the file to a temporary folder and delete it when finished using it. And you need to use tempfile. The advantage of using tempfile is that the temporary files and folders can be deleted by themselves after the process is done.
import tempfile
path_temp = 'temp' # specify a customed tempory folder that you'd like to use
path_tempCaseFolder = tempfile.TemporaryDirectory(dir=path_temp) # create a temporary folder in the customed folder
path_okr_DNA = tempfile.NamedTemporaryFile(suffix='.txt',dir=path_tempCaseFolder.name).name # generate a txt file in the temporary folder. note that you need to use name to get the path of the temporary file and folder
Structure the project folder
If you have a complicated structrue for a project and you use relative package in the submodule, then you can run the python file in a submodule. It give you the error like ImportError: attempted relative import with no known parent package. That’s because this file don’t know the current package. If you write the code in the file print(__package__), it will return None. So it don’t known the parent package. But if you want to run the submodule in a script that locates in a upper level, then you have to use the relative package mode to let the submodule know where it locates. If you ran it on a upper level. Then the package will be the folder name that the submodule locates.
In order to solve this problem, you’d better use pathlib and sys to locate the package to the project folder not the submodule.
import sys
import pathlib
sys.path.insert(0,str(pathlib.Path(__file__).resolve().parent.parent)) # you need to specify how many parent you should use to locate to the project folder
At last, you can use the submodule independent or in an upper level script file.
install packages
conda
conda install package_name=version
conda install 'package_name>= version'
conda install 'package_name<= version'
If any of these characters, ‘>’, ‘<’, ‘ ’ or ‘*’, are used, a single or double quotes must be used
Python
使用dateutil 对string转换成datetime
from dateutil import parser
import pandas as pd
s = '7/1/2021 6:29'
parser.parse(s)
# output: datetime.datetime(2021, 7, 1, 6, 29)
parser.parse(s).strftime('%m/%d/%Y')
# output: '07/01/2021'
# calculate the TAT. the endDate and startDate are datetime style
tat = round((endDate-startDate)/pd.Timedelta(hours=24), 1)
Now you can use the result get what kind of format you’d like to convert. This package is easy and friendly. It just convert the string to datetime directly.
使用yml格式作为config 文件格式
ymal : “Yet Another Makeup Language”
- install:
pip install PyYAML - import :
import yaml - load :
with open('config.yml','r') as f: config = ymal.safe_load(f) - dump : ‘with open(‘config.yml’,’w’) as f: config = ymal.safe_dump(f)’
use shutil to copy files
When I use VSCode to link the remote server and run code in VSCode. The code shutil.copy(path_src,path_dest) will show errors that Permission Deny. Anyway you can’t copy files to some directory. 如果换了文件夹,则可以成功复制。后面使用shutil.copyfile(file_src,file_dest)则没有问题。
use pipreqs to extract the packages used in the script
pip3 install pipreqs
pipreqs ./your_script_directory
use glob to search specific files in specific depth
If you don’t care about the depth of the dictionary, then you can use pathlib.Path.rglob(pattern) to search the files. But the problem is that when the file or path has a long name, this method will generate error. Another method is to use glob to search the files with a specific depth in the dictionary. Show as below.
from pathlib import Path
import os,glob
pattern_file = r'Chip Loading*.xlsm'
path_folder = Path(/mnt/hgsf/test)
list_desiredFiles = path_folder.rglob(pattern_file)
# another method
#zero depth
list_desiredFiles_d0 = glob.glob(os.path.join(path_folder,pattern))
list_desiredFiles_d1 = glob.glob(os.path.join(path_folder,'*',pattern))
list_desiredFiles_d2 = glob.glob(os.path.join(path_folder,'*','*' ,pattern)) # how many star * means how many depths of the dictionary
use * to unpack the list
for a in zip([[1,2,3],[4,5,6]]):
print(a)
# output
#([1, 2, 3],)
#([4, 5, 6],)
for a in zip(*[[1,2,3],[4,5,6]]): # add * to unpack a list
print(a)
# output
#(1, 4)
#(2, 5)
#(3, 6)
format string
score = 0.7777777
print('The score is %.3f'%score) # output : The score is 0.778
print space
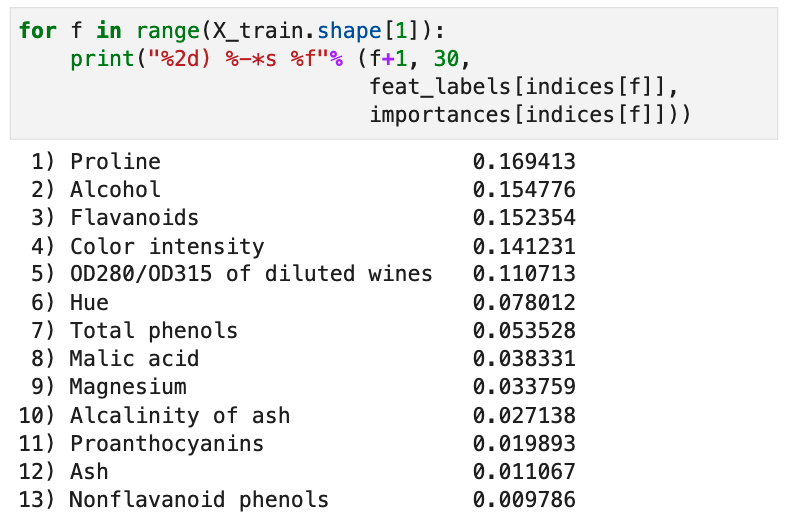
for f in range(X_train.shape[1]):
print("%2d) %-*s %f"% (f+1, 30,
feat_labels[indices[f]],
importances[indices[f]]))
以上代码中,
%2d)对应的是1),%-*对应的是30个space,这里的*对应30,前面的负号(-)表示是在文字后使用空格填补30个字符,如果不加负号则是在文字前面填补空格到30个字符。s对应的是feat_labels[indices[f]]%f对应的是importances[indices[f]]
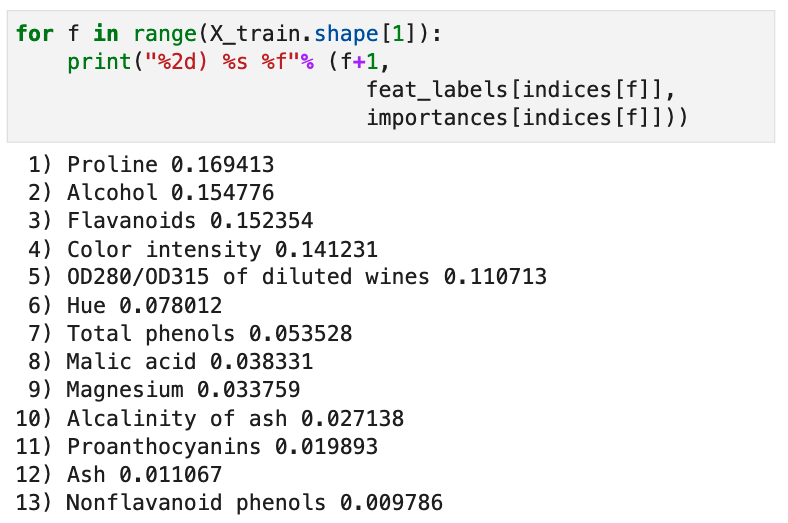
以下是string 没有添加空格后的效果
set
defaultdict
from collections import defaultdict
dic_count = defaultdict(int) # 用于计数, default value is 0
dic_list = defaultdict(list) # 用于储存数组, default value is [],a empty list
dic_labmda = defaultdict(lambda : 'ok')
# default value is the return value in the lambda, here is 'ok',
# you can also set other values such as empty string, float('inf')
两个defaultdict在一起使用需要使用lambda,例如: table_food = defaultdict( lambda : defaultdict(int) ),如果不使用lambda,defaultdict(defaultdict(int))是会报错的。例如1418. 点菜展示表
bisect
bisect.bisect_left(stack,idx):通过2分法排序查找idx 在stack中位置(从左边开始),若bisect.bisect_right(stack,idx)则是从右边开始数。
import bisect
a = [1,2,3,4,5]
bisect.bisect_left(a,3)
# output : 2
bisect.bisect_right(a,3)
# output : 3
sort OR sorted
a = ['ok','as','apple','pear','desk']
b = sorted([(word,len(word)) for word in a], key=lambda x: (-x[1],x[0]))
# output of b :[('apple', 5), ('desk', 4), ('pear', 4), ('as', 2), ('ok', 2)]
Note:通过 key 对关键字进行排序,首先是单词中字符的数量x[1],之所以加
-是因为想让字符数量从大到小排列,而相同字符数量的单词,则是按照单词在单词字典中的顺序排列。例如abe 要排在 abm 之前。
range
for i in range(3,0,-1):
print(i)
# output : 3,2,1
for i in range(0,10,2):
print(i)
#output : 0,2,4,6,8
ord
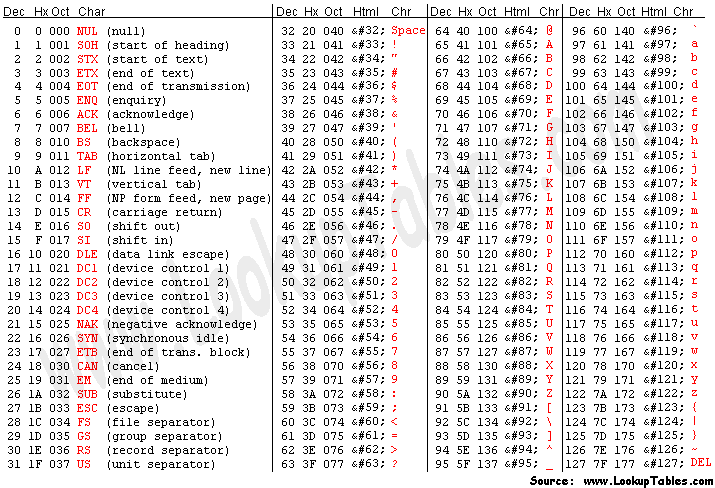
ord("A") -> 65:字符转化为ASCII码(十进制)chr(65) -> 'A': ASCII 转化为字符
heapq
堆堆数组进行heapify后可以保证数组index=0为最小的值,因此python自带的heapq属于小顶堆。每次heappop, heappush 都会改变数组中数值的排列。
如果想要大顶堆,可以在每个数组中的数前加上-号,提取出来时再加上-即可。
import heapq
ls = list([1, 3, 5, 7, 9, 2, 4, 6, 8, 0])
heapq.heapify(ls) # 堆化,此时ls的element的顺序发生变化,排在ls[0] 是ls中最小的一个数
ls
# output : [0, 1, 2, 6, 3, 5, 4, 7, 8, 9]
heapq.heappop(ls) # 弹出最小的数,此时ls中的数据也发生变化
ls
# output: [1, 3, 2, 6, 9, 5, 4, 7, 8]
heapq.heappush(ls,10) # 往堆中加入数据
ls
# output: [1, 3, 2, 6, 9, 5, 4, 7, 8, 10]
deque
python的deque 函数可以行使queue的功能:first in,first out。并且deque可以在两端进行插入数组和排除数据。
from collections import deque
q = deque([1,2,3,4,5])
q.append(0) # 默认增加在数组最右端
q
# output:deque([1, 2, 3, 4, 5, 0])
q.appendleft(9) # 从左端加入
q
# output: deque([9, 1, 2, 3, 4, 5, 0])
q.pop() # 默认从右端排出
# output : 0
q.popleft() # 从左端排出
# output : 9
one line equation
- 如果只有一个if,可以这样写
[x for x in range(10) if x%2 == 0] - 如果既有if又有else,可以这样写
[x if x%2==0 else x*10 for x in range(10)]
re
python使用Regular expression operations。需使用re package。
import re
-
一般我们使用
r'pattern'来表示regular expression 中的pattern。其目的是可以防止\带来的困扰。例如想查找string中是否存在\\,则pattern需要这样写:\\\\orr'\\'。因此使用r 可以让pattern更容易些,也更容易理解,引号里面是什么就是查找什么内容。不需要对特殊字符进行转化。 -
\w: For Unicode (str) patterns, like [a-zA-Z0-9_].表示所有的小写字母,大写字母,0到9的数字和下划线。
re 的使用
re 的使用有两种方式:
- 使用compile方式
prog = re.compile(pattern)
result = prog.match(string)
首先使用re.compile(pattern)生成regular expresssion object。然后再使用re的function,like match(), search()
- 直接使用re的function。function中要有pattern和string。
result = re.match(pattern, string)
这两种方式的结果是相同的。但是如果多次使用regular expression。则使用re.compile 的效率更高。
use the seperator semicolon but the semicolon not in Square brackets
strung = filter(None, re.split(r';(?!)', string))
(?![^\[\]]*\]) is the negative lookahead to assert that ; is not within [...]. However, this regex does not check if the semicolon is really inside the square brackets, it only matches them before a closing square bracket without checking for the opening one
use the seperator semicolon but the semicolon not in parenthese
re.split(''';(?=(?:[^'"]|'[^']*'|"[^"]*")*$)''', data)
Each time it finds a semicolon, the lookahead scans the entire remaining string, making sure there’s an even number of single-quotes and an even number of double-quotes. (Single-quotes inside double-quoted fields, or vice-versa, are ignored.) If the lookahead succeeds, the semicolon is a delimiter.
If the double-quoted and single quotes are odd, then the semicolon must be in the parenthese. So this semicolon will not be treated as a seperator.
匹配多种可能性
使用()和|进行组合匹配多种可能性。如下,reports后面加上?表示s可有可无。(is|are|were|was) 表示这个位置有四种可能性的词。因为使用了()来寻找pattern,因此可以使用output.group(0)表示匹配到的句子或可能的内容。 .*? : 非贪婪匹配。
output = re.search(r'Tax reports? (is|are|were|was) reported .*?(\n|\.)')
output.group(0)
openpyxl
给excel 中的cell填充颜色
from openpyxl.styles import PatternFill
def color_ws_reportDate(ws,column='M'):
"""Color the report date in ws : reported : green , unreported: red
- ws : worksheet opened by openpyxl
"""
fillGreen = PatternFill(fill_type='solid',
start_color='6BCB77',
end_color='6BCB77')
fillRed = PatternFill(fill_type='solid',
start_color='FF6B6B',
end_color='FF6B6B')
for cell in ws[column]:
try:
value = str(cell.value).strip()
if value and value != 'nan':
print(f'value is : {value}')
cell.fill=fillGreen
else:
cell.fill = fillRed
except:
message(f'Error when color report date in cell contain: {cell.value}',bcolors.FAIL)