House Price predidction 回归问题
Table of contents
EDA
sns 做图
本项目的原始feature有80 项,因此可以使用sns.heatmap查看missing value。sns.heatmap就是把二维数组进行颜色展示。,以下代码显示列缺失值的情况:
plt.figure(figsize=(20,8))
sns.heatmap(data = train_data.isna() , cbar=False)

Note:
cbar=False为是否在侧边栏显示color bar。在展示correlation 时,常用参数除了data, cbar还有annot=True, cmap='RdYlGn',linewidths=0.2, annot_kws={'size':14}。
填补缺失值(fill NA)
- 查看缺失值情况:
先根据缺失值的数量做一个排序
pd.options.display.min_rows = 80 # 强制pandas显示80列数据
train_data.isna().sum().sort_values(ascending=False) # 按照降序排列
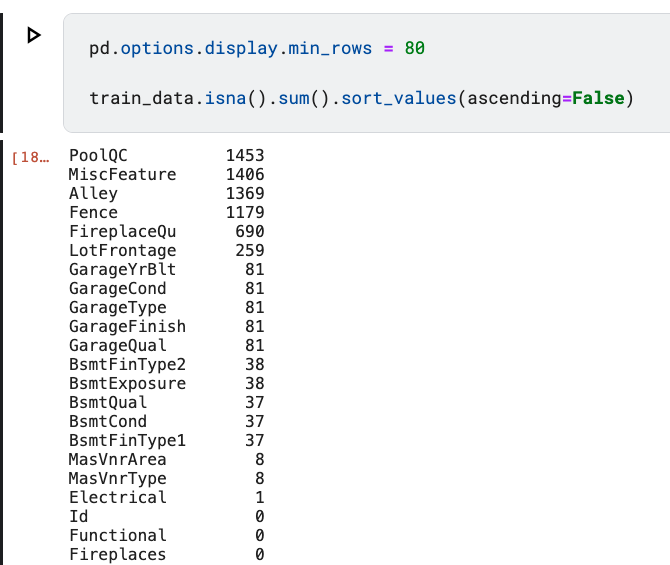
Note:其实
train_data.isna().sum()可以看作是一个dictionary
- 删除含有缺失值过多的列
drop_columns = ['PoolQC','MiscFeature','Alley','Fence','FireplaceQu','LotFrontage','GarageYrBlt']
train_data.drop(columns=drop_columns,inplace=True)
test_data.drop(columns=drop_columns,inplace=True)
填补缺失值,可以把某一类的feature整合在一起,然后编写一个function统一处理。为了少写代码可以使用inplace=True,例如train_data[column_name].fillna('NA', inplace=True)
- 填补缺失值为发生频次最多的value:
train_data[column_name].fillna(train_data[column_name].dropna().mode()[0],inplace=True)
# 也可以写成下面方式
train_data[column_name].fillna(train_data[column_name].mode(dropna=True)[0],inplace=True)
# fill na with mean
train_data[column_name].fillna(train_data[column_name].dropna().mean(), inplace=True)
Note: mode 的具体用法参考dataframe,官方给出的解释是Get the mode(s) of each element along the selected axis. The mode of a set of values is the value that appears most often.It can be multiple values.
mean 的用法参考source,其本身默认参数就是删除掉NA,然后计算其均值。
- 查看categorical features
categorical_feature = [feature for feature in train_data.columns if train_data[feature].dtype == 'O']
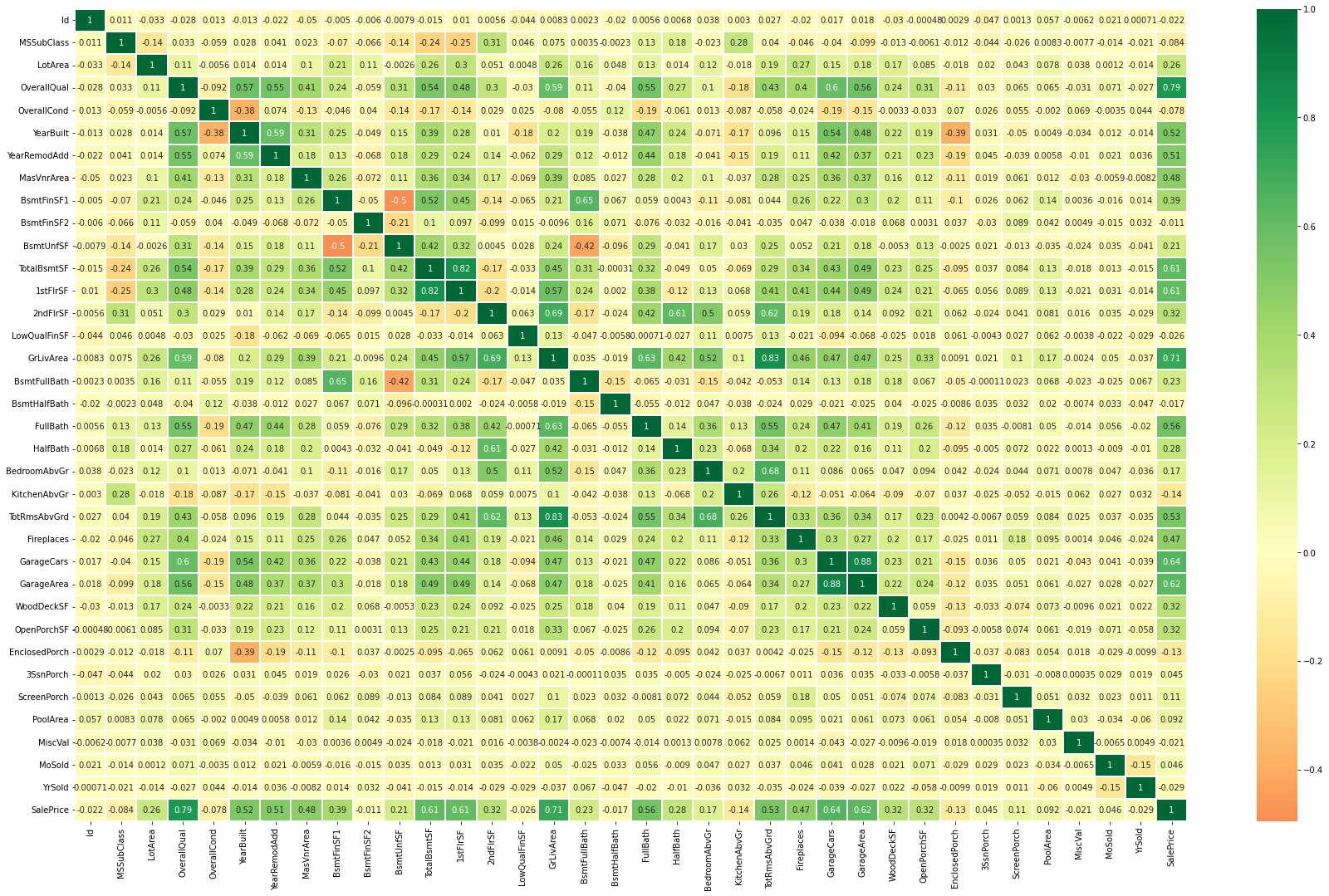
查看 feature correlation
plt.figure(figsize=(30,18))
sns.heatmap(train_data.corr(), center=0, annot = True,cmap='RdYlGn', linewidths=0.2)
Note: sns.heatmap 对numerical feature都可以画图
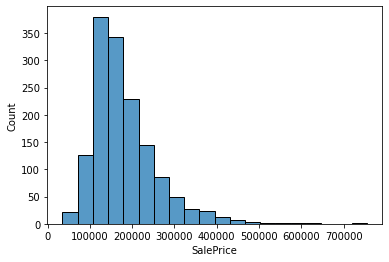
使用hist 查看数据分布
sns.histplot(data=train_data,x = 'SalePrice', bins= 20)
Feature Engineering
先把train_data和test_data 合并在一起同时处理,
data= pd.concat([train_data.assign(ind='train'), test_data.assign(ind='test')],ignore_index=True)
Note:使用data.assign的目的是在后面区分train和test时更方便。
生成新的feature有两个思路:
- 对categorical feature 分等级例如:
def convert_to_numerical(s):
if s == 'NA':
return 0
elif s == 'Po':
return 1
elif s== 'Fa':
return 2
elif s== 'TA':
return 3
elif s=='Gd':
return 4
elif s == 'Ex':
return 5
else:
print(f'{s} not in')
- 生成新的feature,例如
data['totalFSF'] = data['1stFlrSF'] + data['2ndFlrSF']
data['OveralRate'] = data['OverallCond'] + data['OverallQual']
把数据中的categorical feature 进行one-hot 处理
train_index = data['ind'].eq('train')
valid_index = data['ind'].eq('test')
X_ = data.drop(columns = ['SalePrice','ind','Id'])
y = data[data['ind'].eq('train')]['SalePrice']
X = pd.get_dummies(X_,drop_first=True) # 增加drop_first=True, 可以减少feature 的数量
train_X = X[train_index]
valid_X = X[valid_index] # 用于最后的检测
X_train,X_test,y_train,y_test = train_test_split(train_X,y, train_size=0.8, shuffle=True, random_state=41)
Model Selection
models
可用于regression的models如下:
from sklearn.linear_model import LinearRegression
from lightgbm import LGBMRegressor
from xgboost.sklearn import XGBRegressor
from catboost import CatBoostRegressor
from sklearn.linear_model import SGDRegressor
from sklearn.kernel_ridge import KernelRidge
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import BayesianRidge
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import AdaBoostRegressor,BaggingRegressor,ExtraTreesRegressor
from sklearn.ensemble import GradientBoostingRegressor,StackingRegressor # stack is like voting
from sklearn.linear_model import RidgeCV
from sklearn.svm import LinearSVR
评判标准
对于回归问题评判标准为mean_squred_error和r2_score
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.metrics import r2_score
from sklearn.inspection import permutation_importance
为了方便,可以把经常使用的功能写成函数,例如
def get_scores(y,pred):
rmse = (np.sqrt(mean_squared_error(y, pred)))
r2 = r2_score(y, pred)
# print("Testing performance")
# print('RMSE: {:.2f}'.format(rmse))
# print('R2: {:.2f}'.format(r2))
return rmse,r2
def train_model(model):
model_ = model
model_.fit(X_train,y_train)
pred = model_.predict(X_test)
return model_, get_scores(y_test,pred)
选择合适的models
经过筛选,选择了如下的models
model_list = [
# LinearRegression(),
LGBMRegressor(random_state=42),
XGBRegressor(random_state=42),
CatBoostRegressor(random_state=42, verbose=0),
# SGDRegressor(random_state=42),
# KernelRidge(),
ElasticNet(random_state=42),
BayesianRidge(),
GradientBoostingRegressor(random_state=42),
RandomForestRegressor(random_state=42),
# AdaBoostRegressor(random_state=42),
BaggingRegressor(random_state=42),
ExtraTreesRegressor(random_state=42),
# RidgeCV(),
# SVR()
]
model_names = [
# 'LR',
'LGB',
'XGB',
'Cat',
# 'SGDR',
# 'KernelRidge',
'ElasticNet',
'BayRidge',
'GradBR',
'RandomForestR',
# 'AdaBoostR',
'BaggingR',
'ExtraTreesR',
# 'RidgeCV',
# 'SVR'
]
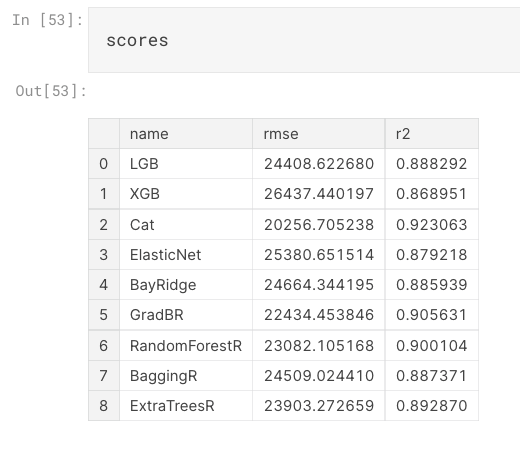
求每个模型的分数
scores = pd.DataFrame(columns=['name' ,'rmse','r2']) # 创建scores dataframe
trained_models = []
for i in range(len(model_names)):
model_,(rmse,r2) = train_model(model_list[i])
trained_models.append(model_)
scores.loc[i] = [model_names[i]] + [rmse,r2] # 把分数添加到scores 中
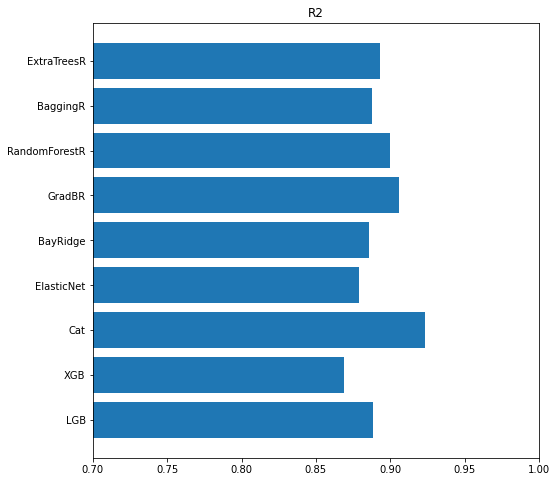
画出scores 中各模型的得分
axis = plt.subplot()
axis.barh(y=scores['name'], width=scores['r2'])
axis.set_xlim([0.7,1.0])
axis.set_title('R2')
fig = plt.gcf()
fig.set_figheight(8)
fig.set_figwidth(8)
plt.show()
VotingRegressor : ensemble models
这时每个模型的分数已经获得,我们来尝试把所有的模型都利用上,我们对所有模型的结果求平均值。
from sklearn.ensemble import VotingRegressor
estimators_tuple = []
for i in range(len(model_names)):
estimators_tuple.append((model_names[i],trained_models[i]))
weights = scores['r2'].values # 这里我们使用每个模型的r2作为这个模型的weights,因为每个模型的可靠性并不相同。
ensemble = VotingRegressor(estimators_tuple,weights=weights)
ensemble.fit(X_train,y_train)
pred = ensemble.predict(X_test)
get_scores(y_test,pred) # output: (20814.515040875984, 0.9187676686082428)
sns.scatterplot(y_test,pred)
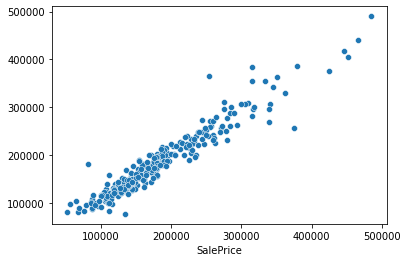
同样的也可以使用点图来查看整体预测情况
plt.figure(figsize=(15,8))
plt.plot(y_test.values,'o', color='blue', label = 'Acutal Values')
plt.plot(pred,'*', color='red', label = 'Predicted Values')
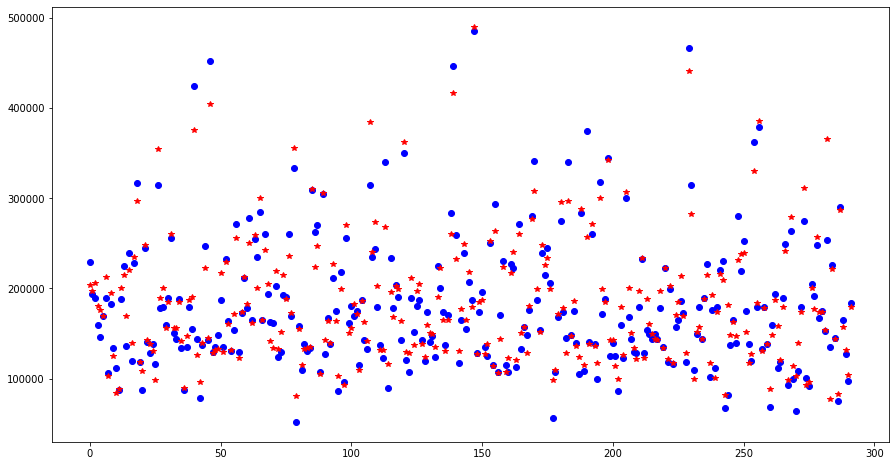
提交结果
这时已经可以提交结果,如下
predictions = ensemble.predict(valid_X)
index = data[data['ind'].eq('test')]['Id'].values
df = pd.DataFrame()
df['Id'] = index
df['SalePrice'] = predictions
df.to_csv('submission.csv', index=False)
但是在多次提交中发现,可以使用所有的train data对ensemble model 进行训练,然后再预测,最终的结果会好一些。
ensemble.fit(train_X,y) # 使用全部的train data 进行训练
predictions = ensemble.predict(valid_X)
index = data[data['ind'].eq('test')]['Id'].values
df = pd.DataFrame()
df['Id'] = index
df['SalePrice'] = predictions
df.to_csv('submission.csv', index=False)